
벤포드 법칙(Benford's law)?
실세계에서 존재하는 많은 수치 데이터의 10진법 값에서 수의 첫째 자리의 확률분포를 관찰한 결과로 첫째 자리 숫자가 작을 확률이 크다는 법칙이다.
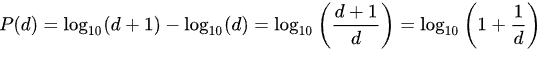
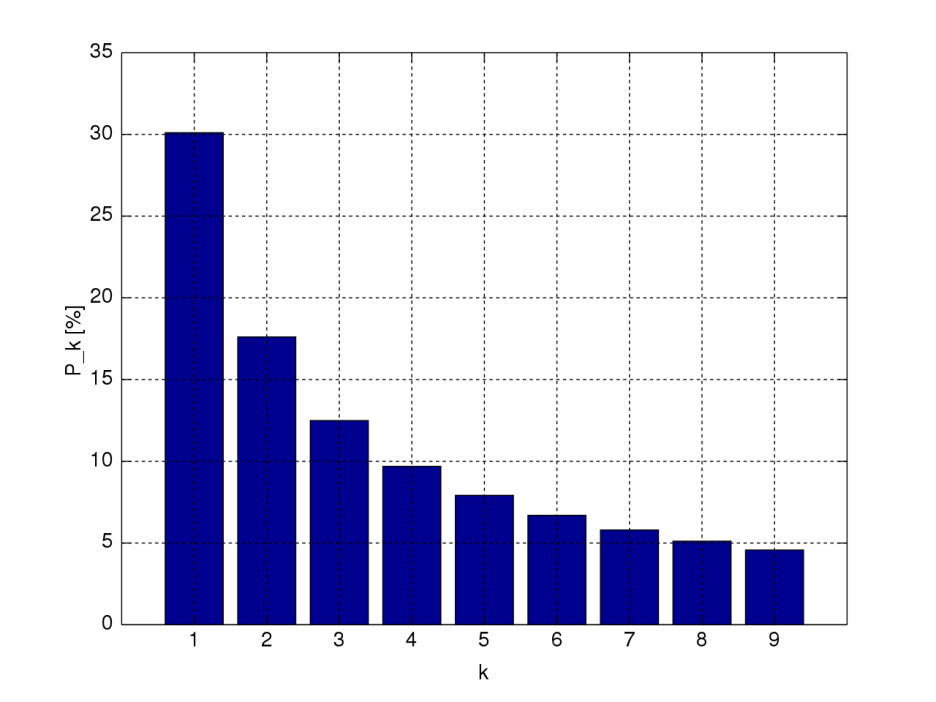
위 표와 마찬가지로 수치 데이터의 수들 중 첫째 자리가 1인 수가 가장 많고 9를 가진수가 가장 적다.
만약 이를 따르지 않을 시 그 수치 데이터는 임의로 조작되었다고 할 수 있다.
(하지만 정확한건 아니므로 참고만 하자)
벤포드 라이브러리 설치
pip install benfordslaw
cmd에 입력하기.
전체 코드
import pandas as pd
from benfordslaw import benfordslaw
df = pd.read_csv('test.csv')
num_of_cases = df.groupby('Classe')['rv'].max()
n_top = num_of_cases.nlargest(10).index
def benford(classe, pos):
global df
df_n = df[df.Classe == classe]
data = df_n['basic']
bl = benfordslaw(alpha=0.05, method='ks', pos=pos, verbose=3)
results = bl.fit(data) # 분석
bl.plot(title=classe+ ', pos: '+str(pos))
for classe in n_top:
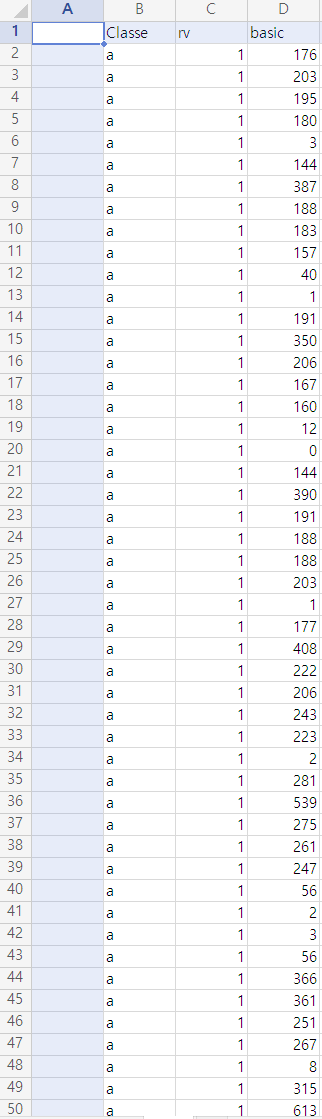
benford(classe, 1)CSV 파일을 읽은 후 자료를 분류하는 방식이며,
자료가 다수일 경우가 있기 때문에 자료들을 Classe 별로 나눈 후 Classe들의 기준값(rv)들을 이용하여 출력 순서를 정하도록 설계하였습니다.
자료 분석
https://ncv.kdca.go.kr/vaccineStatus.es?mid=a11710000000
코로나19 백신 및 예방접종
질병관리청 코로나19 백신 및 예방접종 정보안내
ncv.kdca.go.kr
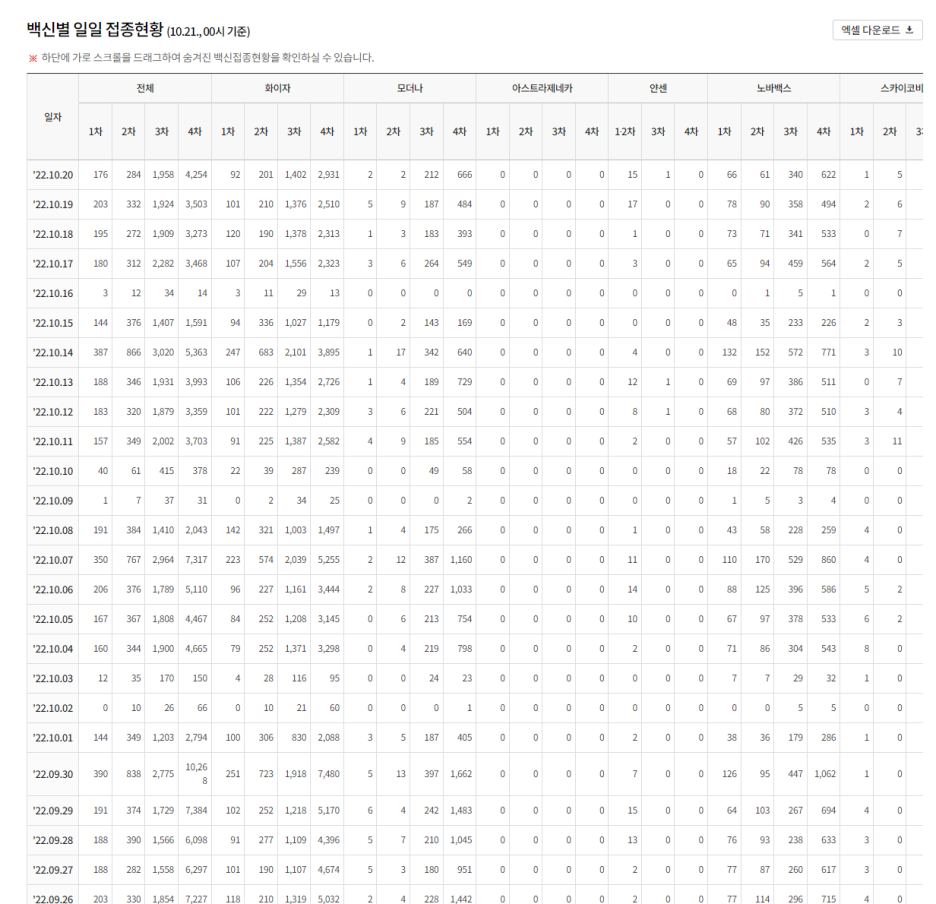
질병관리청에서 나오는 "백신별 일일 접종 현황" 중 1차 전체 백신 접종률(2022.10.20 ~ 2021.02.26)의 자료를 분석해 보았습니다.
Classe: 분류 (ex) 나라, 지역, 부서)
분석 결과
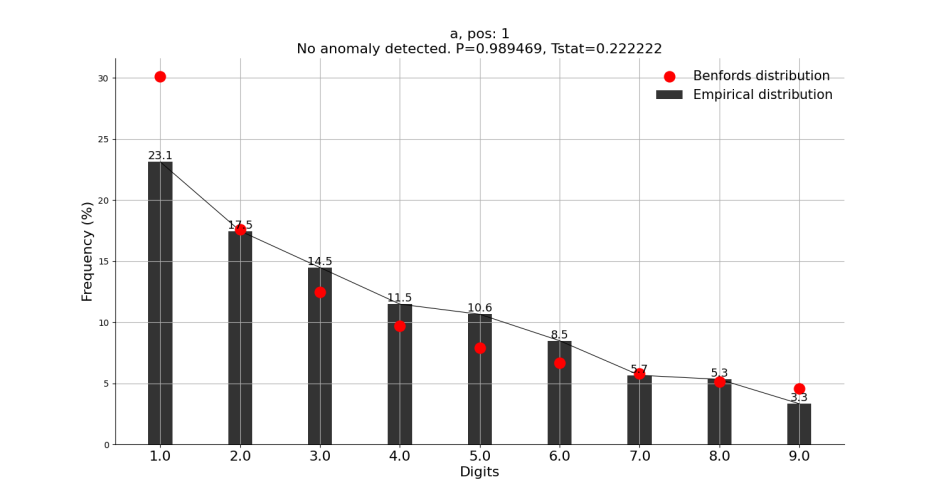
...
...
물론 100% 신뢰는 할 수 없습니다...
(2022.10.20 ~ 2021.02.26) 총 604개의 수치 데이터를 분석했는데... 그래프가 깔끔하지 않네요..
뭐.. 표본이 적은 것도 안인데 이런 결과가 나왔네요..
(100% 정확한 건 아니므로 참고만 하자)
100% 확실한 거짓 판별 프로그램이 아니기 때문에 어디까지나 참고용입니다.
BP_v2.0
GitHub - FURY312/BP_v2.0: 벤포드의 법칙
벤포드의 법칙. Contribute to FURY312/BP_v2.0 development by creating an account on GitHub.
github.com

블로그 쓸려고 테스트하면서 안 건데 한셀에서는 분석 기능이 이미 있네요.. ㅋㅋ
'Python' 카테고리의 다른 글
| [Python파이썬] .txt 파일의 특정 단어 찾기 (우울증 진단 프로그램) (0) | 2022.11.04 |
|---|---|
| [파이썬Python] 문자암호화, 복호화 (암호 발생기 만들기) (0) | 2022.10.22 |
| [Python파이썬] 파일검색, 파일삭제 하는 기능을 이용해서 컴퓨터 시한폭탄 만들기. (0) | 2022.10.22 |
| 파이썬 인스타그램 좋아요 봇 만들기. [Python, 자동 좋아요봇] (0) | 2022.10.19 |
| Python파이썬 특정 지점의 RGB 값을 구하기 (0) | 2022.10.18 |